
Predicting the Dependent Variable Using the Regression Model
In the realm of data analysis, unraveling intricate patterns and relationships within datasets is paramount to gaining profound insights. In this extended analysis, we will embark on a journey into a dataset comprising two pivotal columns, X and Y, to delve deeper into the intricate relationship between them.
Table 1: The X and Y Dataset
Before we immerse ourselves in the intricacies of data analysis, let’s take a moment to acquaint ourselves with the dataset at hand. Here, we encounter a collection of X and Y values, denoting some underlying connection between the two. X stands as the independent variable, while Y assumes the role of the dependent variable.
| X | Y |
|---|---|
| 10 | 25 |
| 15 | 35 |
| 20 | 40 |
| 25 | 55 |
| 30 | 60 |
| 40 | 70 |
| 50 | 80 |
Visualizing the Relationship
Our journey into this data begins with a compelling visualization - the scatter plot. This visualization serves as a window into the heart of the relationship between X and Y, revealing the fundamental nature of their connection.
As evident from the scatter plot, a clear positive linear relationship emerges. This visual cue suggests that as X values ascend, Y values accompany them in a harmonious ascent, signifying a robust correlation between the two variables.
Regression Analysis - The Heart of the Matter
To dissect and quantify this relationship with precision, we turn to the statistical technique of regression analysis. It provides the tools to not only affirm our visual observations but also to uncover nuanced insights. The results of this analysis are displayed in Table 2.
Table 2: Regression Statistics
| Statistic | Value |
|---|---|
| Multiple R | 0.9827 |
| R Square | 0.9658 |
| Adjusted R Square | 0.9589 |
| Standard Error | 4.006 |
| Observations | 7 |
Delving into these statistics reveals the depth of the connection between X and Y:
Multiple R (Multiple Correlation Coefficient): With a value of 0.9827, we confirm our visual assessment of a robust positive correlation. This statistic elucidates the strength of the linear relationship.
R Square (Coefficient of Determination): At 0.9658, this metric informs us that approximately 96.58% of the variance in Y can be ascribed to variations in X. Such a high R Square underscores the potency of X as a predictor of Y in our dataset.
Adjusted R Square: This statistic, standing at 0.9589, reflects the model’s adaptability when considering the number of variables involved. The fact that it remains high reinforces the soundness of our model.
Standard Error: Marking the spread between actual Y values and their corresponding predictions, the standard error is a valuable measure at 4.006.
Observations: The dataset comprises seven data points, underpinning the analysis.
ANOVA (Analysis of Variance) - The Model’s Significance
To appraise the model’s overall significance, we deploy the venerable statistical tool - ANOVA. Its application to our regression model yields Table 3, offering a comprehensive view of the analysis’s validity.
Table 3: ANOVA (Analysis of Variance) Table
| df | SS | MS | F | Significance F | |
|---|---|---|---|---|---|
| Regression | 1 | 2262.617622 | 2262.617622 | 140.9914712 | 7.46229E-05 |
| Residual | 5 | 80.23952096 | 16.04790419 | ||
| Total | 6 | 2342.857143 |
Regression: This row scrutinizes the model’s overarching influence in explaining the dataset’s variance. With a degrees of freedom (df) of 1, it reflects the model’s complexity.
Sum of Squares (SS) for regression (2262.617622) accounts for the total variance elucidated by our model. The Mean Square (MS) is derived by dividing SS by its degrees of freedom, offering an insightful metric for variability within the regression.
The F-statistic (140.9914712) acts as a sentinel, guarding the model’s integrity. It quantifies the ratio of variance clarified by the model against the unexplained variance (residual). A lofty F-value confirms the model’s statistical significance, which is further corroborated by the minuscule Significance F (p-value) of 7.46229E-05. This tiny p-value signals that the regression model is indisputably significant, signifying that the relationship between X and Y isn’t due to mere chance.
Coefficients - The Precise Formula
In Table 4, we examine the coefficients that define our regression model, offering us precise insights into how X and the intercept contribute to the prediction of Y.
Table 4: Coefficients Table
| Coefficients | Standard Error | t Stat | P-value | Lower 95% | Upper 95% | Lower 95.0% | Upper 95.0% | |
|---|---|---|---|---|---|---|---|---|
| Intercept | 14.76047904 | 3.49343596 | 4.225203843 | 0.008286304 | 5.78031602 | 23.74064206 | 5.78031602 | 23.74064206 |
| X Variable 1 | 1.377245509 | 0.115988503 | 11.87398295 | 7.46229E-05 | 1.07908757 | 1.675403448 | 1.07908757 | 1.675403448 |
In Table 4, we unearth the precise formula that describes the relationship:
Intercept: At 14.76047904, the intercept represents the estimated value of Y when X is zero. This value holds valuable insights, revealing the starting point of our relationship.
X Variable 1: The coefficient for X, marked at 1.377245509, portrays the extent to which Y is projected to change for every unit increase in X. In this case, for each unit rise in X, we expect Y to ascend by approximately 1.3772 units.
Standard Error: This metric, found in the same table, stands as a sentinel, guarding the precision of the coefficient estimates.
t Stat (t-Statistic) and P-value: These components confer the statistical significance of each coefficient. In
both instances, the p-values are remarkably low (7.46229E-05), indicating that both the intercept and X Variable 1 hold immense statistical significance as predictors of Y.
Lower 95% and Upper 95%: These columns divulge the lower and upper bounds of the 95% confidence interval for each coefficient. This vital information guides us in assessing the range in which the true coefficient values likely reside, bolstering our confidence in the model.
Implications and Beyond
In this comprehensive analysis, we unearthed a robust positive relationship between X and Y, validated by regression statistics, ANOVA results, and precise coefficient estimates. Our understanding of these statistical measures empowers us to make data-driven decisions and forecasts, unraveling insights that reverberate across a multitude of fields.
The significance of data analysis becomes abundantly clear as we unearth meaningful patterns and insights from raw data. Our exploration of this dataset serves as an inspiring testament to the potency of data analysis in deciphering complex relationships, shedding light on a path toward more informed decisions and innovative solutions.
So, as you venture into the realm of data analysis, remember that beneath the numbers lies a wealth of knowledge, waiting to be revealed.
Predicting with Confidence: Understanding Prediction Intervals in Regression Analysis
Regression analysis is a powerful tool in statistics and data analysis, allowing us to understand and predict relationships between variables. One essential aspect of regression analysis is making predictions, and that’s where prediction intervals come into play. In this blog post, we’ll explore prediction intervals and how they can be calculated using two fundamental equations.
Equation 1: Prediction Interval for Response \(\widehat{y} = \pm \, t_{\frac{\alpha}{2}, n-2} \, \text{SYX} \, \sqrt{1 + \frac{1}{n} + \frac{\left(x_{p} - \overline{x}\right)^2}{\text{SSX}}}\)
Equation 2: Confidence Interval for Response \(\widehat{y} = \pm \, t_{\frac{\alpha}{2}, n-2} \, \text{SYX} \, \sqrt{\frac{1}{n} + \frac{\left(x_{p} - \overline{x}\right)^2}{\text{SSX}}}\)
What are Prediction Intervals?
Prediction intervals are a vital component of regression analysis that help us estimate the range within which we can expect future observations to fall. Unlike confidence intervals, which provide an interval estimate for a population parameter, prediction intervals give us an interval estimate for an individual observation or the mean response.
Understanding the Equations
Let’s break down these equations step by step:
- \(\widehat{y}\) represents the predicted mean response.
- \(t_{\frac{\alpha}{2}, n}\) is the critical t-score, depending on the desired confidence level (\(\alpha\)) and the sample size (\(n\)).
- \(\text{SYX}\) denotes the standard error of the regression, measuring the typical error in the model’s predictions.
- \(x_p\) is the value of the predictor variable for which you want to make a prediction.
- \(\overline{x}\) represents the sample mean of the predictor variable.
- \(\text{SSX}\) is the sum of squares of the predictor variable.
Conclusion
Prediction intervals are valuable tools in regression analysis, providing us with a measure of uncertainty in our predictions. These two equations give you the flexibility to choose the most suitable prediction interval for your specific analysis. Whether you’re forecasting the average response or predicting individual outcomes, understanding and using prediction intervals can enhance the reliability of your regression models.
Confidence Interval and Prediction Interval of Predictions (Excel)
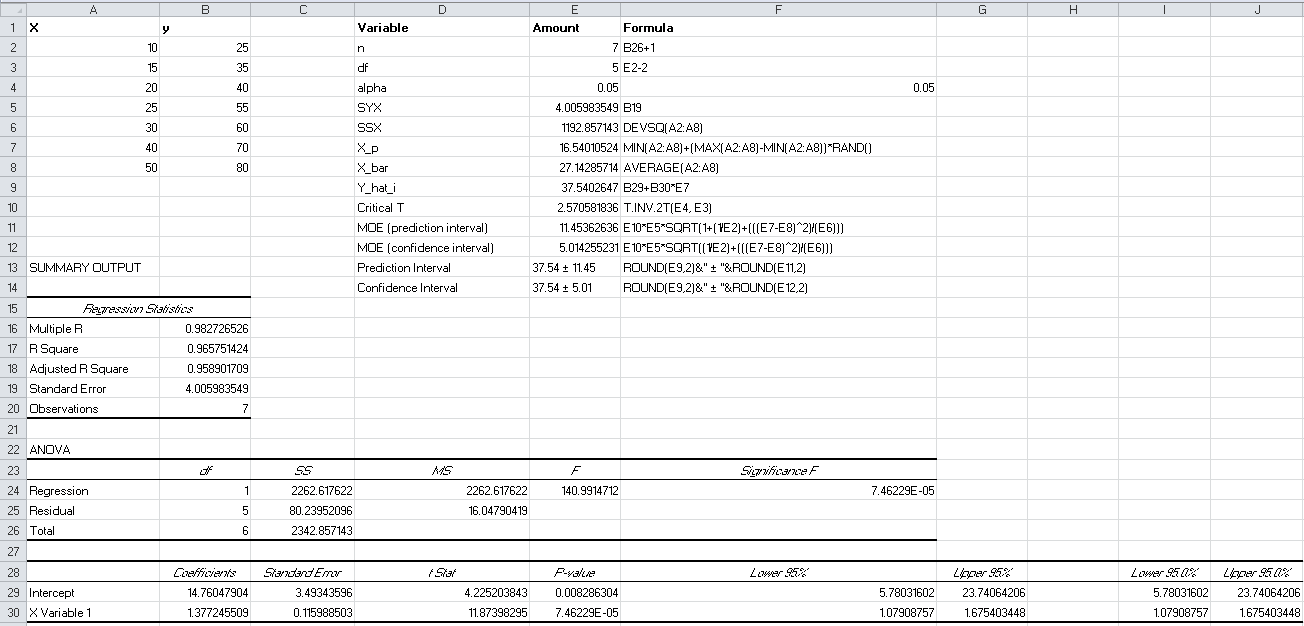
The table provides a comprehensive overview of various variables and their corresponding amounts, along with the formulas used to calculate them in a tabulated format. Notably, it includes essential statistical and mathematical parameters for data analysis. For instance, ‘n’ represents the sample size, calculated as 7. The ‘df’ value signifies degrees of freedom, computed as 5. ‘alpha’ is the significance level, set at 0.05. ‘SYX’ denotes the standard error of the regression, while ‘SSX’ represents the sum of squared deviations. ‘X_p’ is a calculated value using randomization, while ‘X_bar’ represents the sample mean. ‘Y_hat_i’ signifies the predicted value, and ‘Critical T’ is a critical value used in t-distribution. Additionally, the table displays two types of margin of errors (MOE) and corresponding prediction and confidence intervals, providing crucial information for statistical analysis.
Predicting with Confidence: Using Python for Linear Regression
Linear regression is a powerful statistical technique used to model the relationship between a dependent variable (Y) and one or more independent variables (X). It allows us to make predictions based on this relationship. In this blog post, we’ll walk through the process of fitting a simple linear regression model using Python and then using that model to calculate both a 95% confidence interval and a 95% prediction interval for a given value of X.
The Code
We’ll start by importing the necessary libraries, including pandas for data manipulation and statsmodels for the linear regression model. Then, we’ll create a sample dataset and fit a linear regression model to it.
import pandas as pd
import statsmodels.api as sm
# Create a data frame with your data
data = pd.DataFrame({
'X': [10, 15, 20, 25, 30, 40, 50],
'Y': [25, 35, 40, 55, 60, 70, 80]
})
# Fit a linear regression model
X = data['X']
X = sm.add_constant(X) # Add a constant term (intercept) to the model
Y = data['Y']
model = sm.OLS(Y, X).fit()
Once we have our linear regression model, we can use it to make predictions. In this case, we want to predict the value of Y for a given value of X, specifically, when X is 32.62. We create a new data frame new_X with this value.
# Define the value of X for which you want to make predictions
new_X = pd.DataFrame({'const': [1], 'X': [32.62]}) # Adding a constant for the intercept
Now comes the interesting part-calculating the confidence and prediction intervals. A confidence interval gives us a range in which we can be reasonably confident that the true value of Y lies, while a prediction interval is a wider range that accounts for both the uncertainty in our model and the randomness of individual data points.
# Calculate the 95% confidence interval
confidence_interval = model.get_prediction(new_X).conf_int()
# Calculate the 95% prediction interval
prediction_interval = model.get_prediction(new_X).conf_int(obs=True)
Finally, let’s print the results to see our calculated intervals.
# Print the results
print("95% Confidence Interval:")
print(confidence_interval)
print("\n95% Prediction Interval:")
print(prediction_interval)
Predicting with Confidence: Using R for Linear Regression
Linear regression is a fundamental statistical technique used to model the relationship between variables. It enables us to make predictions based on this relationship. In this blog post, we’ll explore how to fit a simple linear regression model using R and then use that model to calculate both a 95% confidence interval and a 95% prediction interval for a specific value of X.
The Code
We’ll start by creating a sample dataset and fitting a linear regression model to it using R. In this example, we have a dataset with two variables, X and Y.
# Create a data frame with your data
data <- data.frame(
X = c(10, 15, 20, 25, 30, 40, 50),
Y = c(25, 35, 40, 55, 60, 70, 80)
)
# Fit a linear regression model
model <- lm(Y ~ X, data = data)
Once we have our linear regression model, we can use it to make predictions. To predict the value of Y for a given value of X (in this case, when X is 32.62), we create a new data frame new_X with this value.
# Define the value of X for which you want to make predictions
new_X <- data.frame(X = 32.62)
Now, let’s calculate the confidence and prediction intervals. A confidence interval provides a range within which we can reasonably expect the true value of Y to fall, while a prediction interval accounts for both the model’s uncertainty and the variability of individual data points.
# Calculate the 95% confidence interval
confidence_interval <- predict(model, newdata = new_X, interval = "confidence", level = 0.95)
# Calculate the 95% prediction interval
prediction_interval <- predict(model, newdata = new_X, interval = "prediction", level = 0.95)
Finally, let’s print the results to see the calculated intervals.
# Print the results
cat("95% Confidence Interval:", confidence_interval, "\n")
cat("95% Prediction Interval:", prediction_interval, "\n")
